JPA는 RDBMS의 table 연관 관계를 Java object로 표현되는 DB model로 표현하기 위해 @OneToMany, @ManyToOne, @Embedded 와 같이 entity 간의 연관 관계를 설정하는 여러 기능을 제공한다.
이는 JPA를 사용하면서 POJO로 이뤄진 Entity와 DB model인 JPA Entity를 굳이 분리하지 않아도 표현력 있는 Entity 코드를 작성할 수 있게 해준다.
이번 포스팅에서는 JPA를 사용했을 때 상위 객체가 하위 객체를 포함하고 있음을 표현하기 위해 @OneToMany로 일대다 관계를 만드는 방식에 대한 얘기를 해보겠다.
여기서는 다대일 관계(many-to-one)에 대해서는 다루지 않겠다.
다대일 관계는 query 효율을 위해 사용할 수 있지만, 개인적인 경험으로는 @ManyToOne, @OneToMany(mappedBy)를 사용한 양방향 연결로 인해 코드의 복잡성이 증가하고, Entity에 JPA 지식이 너무 많이 들어갈 때가 많았다.
또한 다대일 관계로 표현하게 되면 객체 간의 상,하위 역할 관계가 명확하게 드러나지 않는다고 생각한다.
추가로 관련해서 Spring Data JDBC에 대한 발표 영상인 The New Kid on the Block: Spring Data JDBC 를 보기 바란다.
---------------------------------------------
또한 fetch = FetchType.EAGER 를 기준으로 설명하도록 하겠다.
유저가 여러 주소를 가질 수 있음을 다음과 같이 RDMBS의 user table과 address table로 나타낼 수 있다.
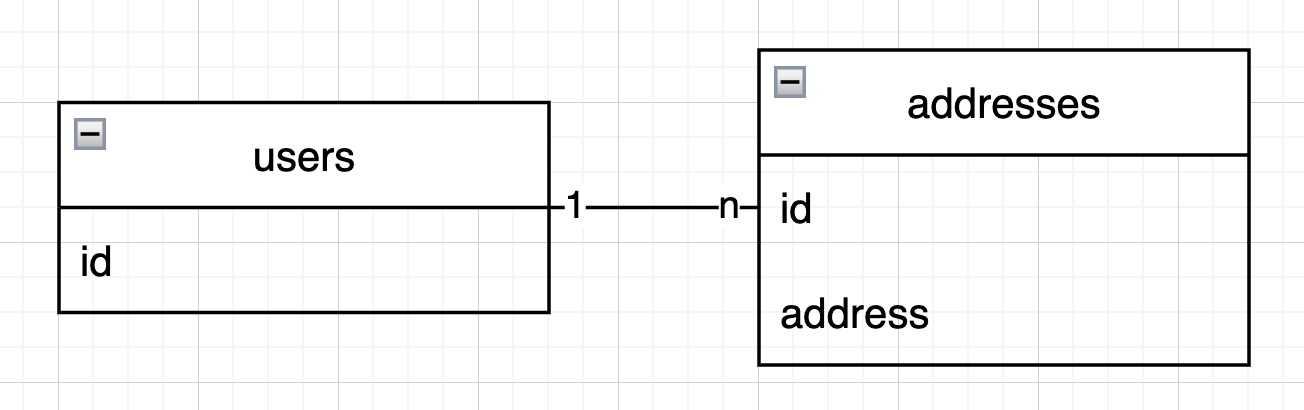
또 이를 아래와 같이 @OneToMany를 사용하여 JPA Entity로 나타낼 수 있을 것이다.
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String name;
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.EAGER)
@JoinColumn(name = "user_id")
private List<Address> addresses = new ArrayList<>();
}
@Entity
@Table(name = "addresses")
public class Address {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String address;
}
코드로 봤을 때는 'User가 여러 Address를 갖는다'는 상,하위 구조가 명확하게 보이므로 명확한 일대다 관계로 볼 수 있다.
Entity 안에 Entity가 있는 꼴이라 Aggregate의 측면에서 봤을 때 의아한 구조일 수 있다.
왜 @ElementCollection를 사용하지 않고 굳이 Address를 Entity로 지정했는가?
이는 유저의 특정 주소를 삭제하거나 업데이트 등을 해야하는 경우를 위해, 유저가 등록한 주소들 중에 특정 주소를 선택할 수 있게하기 위함이다.
이와 관련해서는 뒤에 다시 얘기할테니 일단 넘어가자.
위 Entity 코드는 봤을 때 구성도 나쁘지 않아 보이고, 어노테이션을 봤을 때 동작도 잘 할 것 같다.
하지만 문제는 Entity를 영속화할 때 발생한다.
아래와 같이 Address가 3개 있는 User를 생성한 뒤 저장한다고 하면, query가 몇 개 발생할까?
System.out.println("== save user with 3 addresses");
User user = new User()
.addAddress(new Address("서울"))
.addAddress(new Address("인천"))
.addAddress(new Address("제주"));
userRepository.save(user);
System.out.println("// == save user with 3 addresses");총 7개의 query가 발생한다.
⓵ 먼저 상위 Entity인 User를 insert 하고
⓶ User 하위 Address들이 하나 씩 join column인 User의 id가 우선 null로 지정되어 insert된 뒤,
⓷ join column이 User의 id로 update되기 때문이다.

즉, @OneToMany를 설정한 뒤 insert를 하게되면 실행되는 query는 1 + 2N 개(N은 하위 Entity의 개수) 라고 볼 수 있다.
이렇게되면 갖고있는 하위 Entity가 많으면 많을 수록 query가 그 수에 비례하여 증가하게 되고,
join column이 처음에 null로 insert 되기 때문에 join column에 not null 제약을 걸 수 없다.
또 상위 Entity가 기존에 있던 하위 Entity를 모두 없애고 새로 하위 Entity를 추가한다고 해보자.
System.out.println("== remove user's all addresses and add 1 address");
user.removeAllAddresses() // 하위 Entity 모두 제거 (3개 저장되어있음)
.addAddress(new Address("강원")); // 하위 Entity 추가
userRepository.save(user);
System.out.println("// == remove user's all addresses and add 1 address");
정말 간단한 코드인데도 (select 문을 제외하고)query가 무려 8개나 실행되는 무거운 작업이 되었다.
(@OneToMany(orphanRemoval = false) 라면 delete query는 실행되지 않는다)
이는 상위 Entity가 포함하고 있는 하위 Entity의 추가, 삭제가 빈번하게 일어나는 경우에 @OneToMany를 설정하는 것이 좋지않다는 것을 보여준다.
마지막으로 조회 쪽을 살펴보자.
System.out.println("== find by id");
System.out.println(
userRepository.findById(user1.getId())
);
System.out.println("// == find by id");
System.out.println();
System.out.println("== find all by id in");
System.out.println(
userRepository.findAllByIdIn(List.of(user1.getId(), user2.getId()))
);
System.out.println("// == find all by id in");
id로 특정 상위 Entity를 조회하는 경우는 left join을 하기 때문에 query를 단 하나만 사용한다.
하지만 findAll~~와 같이 여러 건의 상위 Entity를 조회하는 경우,
⓵ 상위 Entity를 모두 조회한 뒤,
⓶ 조회된 상위 Entity 별로 연관된 하위 Entity들을 조회한다.
즉, 여러 건의 상위 Entity들을 조회할 수록 query가 많아진다는 것이다.
지금까지 JPA를 사용하면서 @OneToMany로 일대다 관계를 맺는 방식과 관련하여 여러가지로 알아보았다.
앞서 살펴본 것 처럼 Entity간에 상,하위 관계를 표현하기 위해 @OneToMany 관계를 맺는 것은 여러모로 오버헤드가 추가로 발생한다.
Entity간에 직접 연관 관계를 맺지않고, VO를 만들고 @ElementCollection을 쓸 수 있겠지만 실무에서 쓰는 건 아직 보진 못했다.
그리고 데이터는 특정할 수 있어야하는데 @ElementCollection를 쓰면 하위 객체가 id를 갖지 못하기 때문에, 이를 쓸바엔 차라리 @OneToMany를 쓰는 것이 데이터 관리에 있어 좋은 방향은 아닐까 생각한다. 🤔
결과적으로 JPA를 사용하면서 @OneToMany를 쓰고자 할 때는 조심스럽게 접근하는 것이 좋다.
되도록이면 Entity 간에 직접적인 연관 관계를 갖지 말고, id를 통해 간접 참조를 하는 식으로 접근하는 것이 앞서 말한 여러가지 오버헤드를 피하기에 좋다.
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
// @OneToMany(cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.EAGER)
// @JoinColumn(name = "user_id")
// private List<Address> addresses = new ArrayList<>();
}
@Entity
@Table(name = "addresses")
public class Address {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private Long userId; // <- id 간접 참조
@Column
private String address;
}
하지만 그럼에도 @OneToMany를 쓴다고 하면 하위 Entity와 관련된 변경이 매우 드물고 append만 하는 유스케이스에 사용하는 것이 좋고,
여러 Entity를 조회해야하는 경우에는 Entity를 직접 조회하기 보다는 QueryDSL 등으로 쿼리 결과를 DTO에 담아서 사용하는 것이 좋을 것이다.
추가로 참고하면 좋은 링크
- JPA 일대다 단방향 매핑 잘못 사용하면 벌어지는 일
'Java & Kotlin > Spring' 카테고리의 다른 글
| Kotlin SpringBoot 환경에서 jOOQ 설정 (2) | 2024.12.03 |
|---|---|
| [Spring] Swagger UI 대신 Scalar API Reference를 사용하여 API 문서 사용하기 (1) | 2024.10.29 |
| [Spring Data JPA] entity update 후 JpaRepository.save 호출에 관하여 (6) | 2023.01.09 |
| [springdoc-openapi] 고정 header 설정하기 (0) | 2022.12.31 |
| Request Rate Limiting with Spring Cloud Gateway - 부록. custom Filter 만들기 (0) | 2022.02.08 |



댓글